
tg-me.com/nlp_stuff/168
Last Update:
معماری تماما MLP برای پردازش تصویر
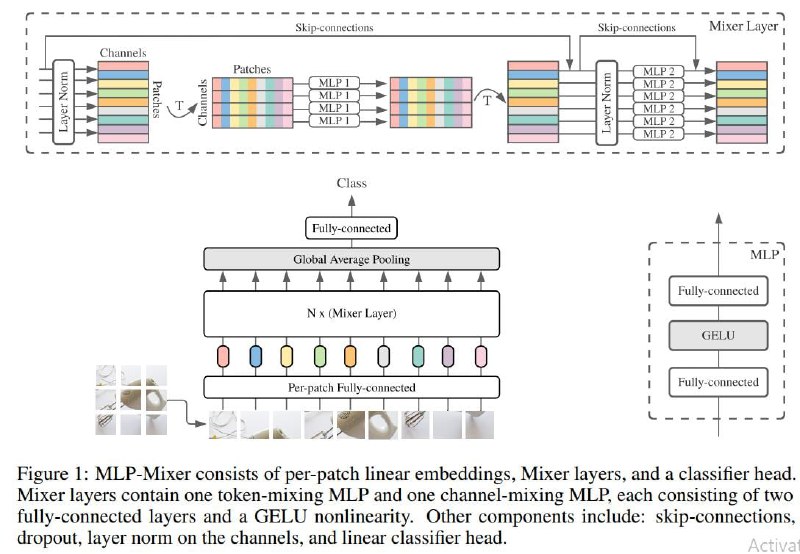
پست امروز درباره یک معماری ساده است که همین دو روز پیش مقالهاش منتشر شده. این معماری برای تسک دستهبندی تصاویر ارائه شده و بر خلاف شبکههای نامداری مثل ResNet و ViT هیچ گونه کانولوشن و اتنشی درون خودش نداره و تماما از MLP تشکیل شده. خیلی خلاصه بخوایم توضیح بدیم، ابتدا مثل ViT میاد و تصویر رو به تکه (patch) هایی تقسیم میکنه، سپس بعد از عبور دادن این پچها از لایهی امبدینگ و به دست آوردن یک وکتور برای هر یک از تکهها، اونها رو از N تا لایه به اسم MixerLayer میگذرونه. این MixerLayer درون خودش از دو تا شبکه MLP تشکیل شده که اولیش میاد یک فیدفوروارد روی یک جنبه از تماما تصویرها میزنه (در واقع یک فیچر از روی یک فیچر تمامی تکهها درست میکنه) و دومین MLP هم میاد یک فیدفوروارد از روی فیچرهای یک تکه درست میکنه (شکل پیوست شده رو اگر ببینید درکش بسیار راحته، به اون T یا Transpose ها فقط باید دقت کنید) در نهایت هم به یک شبکه رسیدند و آزمایشهای مختلف پیشآزمایش و فاین تیون رو روش انجام دادند.
شبکه اش از نظر دقتی خاص و برجسته نیست و البته پرت هم نیست. نقطه مثبتش رو میشه نرخ توان عملیاتی بالاش (throughput) دونست که خیلی از شبکههای مثل ViT بهتره (یک دلیلش میتونه این باشه که توی ViT به خاطر وجود اتنشن با افزایش رزولشن و در نتیجه افزایش تعداد تکهها و طول ورودی، میزان نیاز به حافظه به صورت توان دویی زیاد میشه ولی اینجا این اتفاق به صورت خطی رخ میده).
کلا مقاله جالبیه و خب البته سوالاتی رو هم برمیانگیزه که چطوری بدون سوگیری القایی (inductive bias) خاصی به این نتیجه رسیده.
مثل همیشه یانیک کیلچر هم به سرعت یک ویدئو در توضیح این مقاله بیرون داده که میتونید تماشا کنید:
https://www.youtube.com/watch?v=7K4Z8RqjWIk
لینک مقاله:
https://arxiv.org/abs/2105.01601v1
#read
#paper
#watch
@nlp_stuff
BY NLP stuff
Share with your friend now:
tg-me.com/nlp_stuff/168